
تخيل أنك تعمل مع مئات الصفحات الممسوحة ضوئيًا أو ملفات PDF القائمة على الصور وتدرك أنك غير قادر على نسخ أو البحث عن أي نص بداخلها. إنه أمر محبط عندما تحتاج فقط إلى استخراج المعلومات بسرعة أو بناء سير عمل آلي. يُغير DeepSeek ذلك من خلال تحويل المستندات الممسوحة ضوئيًا إلى نص قابل للقراءة آليًا باستخدام تقنية التعرف البصري على الحروف المتقدمة.
سواء كنت تريد معالجة ملفات PDF طويلة، أو الاتصال عبر واجهة برمجة تطبيقات DeepSeek OCR، أو استكشاف موارد GitHub الخاصة به، سيرشدك هذا الدليل خلال كل شيء. ستكتشف أيضًا بديلاً أبسط للتعرف البصري على الحروف بدون كود لتنظيف ملفات PDF على الفور واستخراج النصوص متعددة اللغات.
في هذا المقال
- إجابة سريعة
- ما هو DeepSeek OCR؟
- واجهة برمجة تطبيقات DeepSeek OCR — كيفية استدعائها
- DeepSeek OCR على GitHub — استنساخ وتشغيل محليًا
- استخدام DeepSeek OCR لملفات PDF
- Ollama + DeepSeek OCR (فكرة محلية أولاً)
- مسار أسرع للفرق اليومية: PDFelement (التعرف البصري على الحروف وتنظيف PDF بدون كود)
- DeepSeek OCR مقابل PDFelement مقابل OCR التقليدي — متى تستخدم ماذا
- دليل خطوة بخطوة (جاهز للنسخ)
- اعتبارات معروفة (الدقة، الأمان، التوفر)
الجزء 1. إجابة سريعة
DeepSeek-OCR هو برنامج مفتوح المصدر يستخدم "الضغط البصري" لمعالجة المستندات الضخمة بسياق طويل للغاية. إنه الأفضل للمطورين الذين يحتاجون إلى استخراج واسع النطاق وهو متاح على GitHub مع وثائق API كاملة على الإنترنت. بالنسبة لمعظم الفرق التي تتطلب OCR متعدد اللغات مع واجهة مستخدم رسومية بسيطة، تعتبر ميزات OCR وتحسين المسح الضوئي في PDFelement أكثر عملية. اختر DeepSeek لكفاءة الرموز واختر PDFelement لاستخراج نصوص PDF اليومي والتنظيف عبر أدوات سهلة الاستخدام.
الجزء 2. ما هو DeepSeek OCR؟
يحول هذا النظام المستندات إلى رموز مرئية مضغوطة ويمكّن معالجة سياق طويل فائقة الكفاءة للذكاء الاصطناعي. يحافظ على بنية التخطيط المعقدة، ويقلل تكاليف الرموز، وينتج نصًا جاهزًا للتحليل. لمساعدة نماذج اللغة على التعامل مع المستندات الأطول في عملية واحدة، يضغط الصفحات في عرض مرئي. يدعم المستندات متعددة اللغات والأشكال المختلطة عبر سير العمل البحثي والمؤسسي والتطويري. دعونا نلقي نظرة على بعض القدرات والفوائد الرئيسية التي تقدمها هذه الأداة.

- محرك الضغط البصري: يحول الصفحات إلى رموز مرئية مضغوطة بحيث تعالج نماذج اللغة سياقات أطول بكثير.
- تقليل الرموز بمقدار 10 أضعاف: يقلل عدد الرموز بحوالي عشرة أضعاف مع الحفاظ على تعرف قوي عبر تخطيطات المستندات المتنوعة.
- معالجة عالية الإنتاجية: تقدم إنتاجية عالية لأعباء العمل متعددة الصفحات باستخدام استراتيجيات محسنة للتقسيم والتجميع والتخزين المؤقت.
- أوضاع/دقة ديناميكية: تتكيف الدقة والعروض مع ملفات PDF العلمية والفواتير والجداول والرسوم البيانية والملفات ذات المخططات الكثيفة.
- مخرجات منظمة: تنتج Markdown منظم أو JSON للحفاظ على الجداول والقوائم والرسوم البيانية والتسلسل الهرمي العام للمستند.
يمكنك استكشاف النظرة العامة الكاملة للبحث وعينات الكود في مستودع GitHub الرسمي لـ DeepSeek والأوراق التقنية.


الجزء 3. واجهة برمجة تطبيقات DeepSeek OCR — كيفية استدعائها
تسمح واجهة برمجة تطبيقات DeepSeek OCR للمطورين بدمج معالجة المستندات المتقدمة في سير العمل الخاص بهم. وهي سهلة الوصول للمطورين المألوفين مع SDK من OpenAI، دون الحاجة إلى فهم تنسيق API جديد تمامًا، وذلك بفضل توافقها مع OpenAI. يمكن للمستخدمين إرسال صفحات ممسوحة ضوئيًا أو صور أو ملفات PDF واستلام مخرجات نصية منظمة باستخدام هذه الواجهة. النتائج جاهزة لسير عمل الذكاء الاصطناعي أو قواعد المعرفة أو خطوط أنابيب البحث.
تنسيق API وبنية الطلب
تستخدم واجهة البرمجة بنية طلب HTTP قياسية متوافقة مع SDK بأسلوب OpenAI. يتضمن الطلب النموذجي:
- عنوان URL للنقطة النهائية: نقطة النهاية للواجهة البرمجية حيث ترسل طلبات معالجة المستندات، على سبيل المثال، https://api.deepseek.com/v1/ocr.
- الرؤوس: تتضمن رمز Bearer الخاص بك وأي تفاصيل مصادقة مطلوبة للوصول.
- ملف الإدخال: قدم إما صورة محملة، أو صفحة PDF، أو عنوان URL عام لمعالجة OCR.
- معلمات اختيارية: حدد اللغة، أو وضع التخطيط، أو الدقة، أو تفضيلات أخرى للحصول على نتائج أفضل.
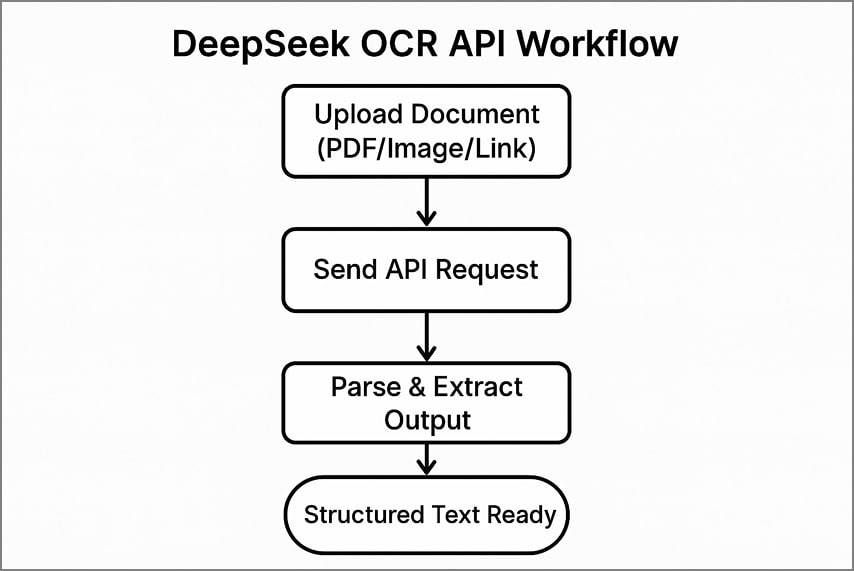
سير عمل API النموذجي
يتضمن استخدام DeepSeek OCR للواجهة البرمجية 3 خطوات واضحة لمعالجة المستندات واستخراج النص المنظم.
- قم بتحميل مستندك إلى واجهة البرمجة بإرسال ملف، أو صفحة PDF، أو رابط عام.
- أرسل استدعاء API مع رؤوس المصادقة الخاصة بك والخيارات المختارة للمعالجة.
- قم بتحليل JSON المُرجع أو النص لاستخراج المحتوى المعترف به وتفاصيل التخطيط والرموز المرئية بدقة.
حدود المعدل والتوافر والموثوقية
على الرغم من قوة API، يجب أن يكون المطورون على دراية ببعض الاعتبارات التشغيلية:
- توفر الخدمة: أظهرت واجهة البرمجة تقلبات عرضية في وقت التشغيل، لذا خطط لاحتمال توقف الخدمة أو أوقات استجابة أبطأ في الإنتاج.
- حدود المعدل: عند التعامل مع المعالجة واسعة النطاق، قد تصل إلى حد المعدل اليومي أو لكل دقيقة، وبالتالي اتخاذ إعادة المحاولات كوسيلة لتوقيت التراجع للحفاظ على الاستمرارية.
- معالجة الأخطاء: تحقق دائمًا من الردود بحثًا عن الأخطاء وتعامل مع الاستثناءات بأناقة لتجنب فشل سير العمل في الإنتاج.

الجزء 4. DeepSeek OCR على GitHub — استنساخ وتشغيل محليًا
سنستكشف كيف يمكنك تثبيت DeepSeek OCR GitHub محليًا من خلال إعداد بيئة Python بعد استنساخ المستودع.
الوصول إلى المستودع
DeepSeek OCR متاح كمشروع مفتوح المصدر على GitHub الذي يوفر للمطورين وصولاً كاملاً إلى هيكله وبرامجه النصية. يتضمن المستودع ملفات تكوين البيئة والوثائق للنشر أو التخصيص. موزع بموجب ترخيص متساهل، فهو يدعم كلاً من البحث والاستخدام الإنتاجي. لدى المشروع مجتمع نشط يساهم بانتظام في إصلاح الأخطاء وتحسينات سير العمل للنشر المحلي.

الإعداد المحلي (أوامر خطوة بخطوة)
لتثبيت DeepSeek OCR محليًا، ما عليك سوى استنساخ المستودع وإعداد Python الخاص بك:
"git clone https://github.com/deepseek-ai/DeepSeek-OCR
cd DeepSeek-OCR
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install -r requirements.txt"
الأداة متوافقة مع Python الإصدار 3.9 أو الإصدارات اللاحقة. يمكن تنزيل أوزان النموذج تلقائيًا عند الاستخدام الأول أو يدويًا عبر روابط في ملف README.
متطلبات وحدة معالجة الرسومات وملاحظات الأداء
يمكن تشغيل DeepSeek OCR على وحدة المعالجة المركزية، على الرغم من أنه يُوصى بشدة باستخدام وحدة معالجة رسومات متوافقة مع CUDA لمعالجة أعباء عمل OCR ذات الحجم الكبير. في المقارنات الداخلية، هناك إمكانية لتحقيق إنتاجية أسرع بـ 5-10 مرات على ملفات PDF متعددة الصفحات أو تخطيطات المستندات المعقدة باستخدام تسريع وحدة معالجة الرسومات. للحصول على الأداء الأمثل، تأكد من تحديث برامج تشغيل NVIDIA وCUDA وإصدارات PyTorch.
تشغيل الاستدلال على ملفات PDF
بعد إكمال الإعداد، اختبر ملف PDF نموذجي باستخدام الأمر التالي:
"python infer.py --input sample.pdf --output output.json"
تتم معالجة كل صفحة كصورة ومعالجتها من خلال خط أنابيب الرؤية VL2 للكشف عن النص والاحتفاظ بالتخطيط. يتكامل مخرج JSON أو Markdown المنظم في سير عمل RAG أو سير عمل LLM المحلي المستند إلى Ollama.
الجزء 5. استخدام DeepSeek OCR لملفات PDF
دعونا نلقي نظرة على كيفية استخدام المطورين بشكل شائع لطرق DeepSeek OCR PDF لاستخراج نص دقيق وبيانات تخطيط من المستندات الممسوحة ضوئيًا أو الرقمية.
الطرق التي يستخدمها المطورون اليوم
بالنسبة لملفات PDF، هناك طريقتان عمليتان يتم تشغيل DeepSeek بهما اليوم، اعتمادًا على مقايضات الجودة والتكلفة والتأخير.
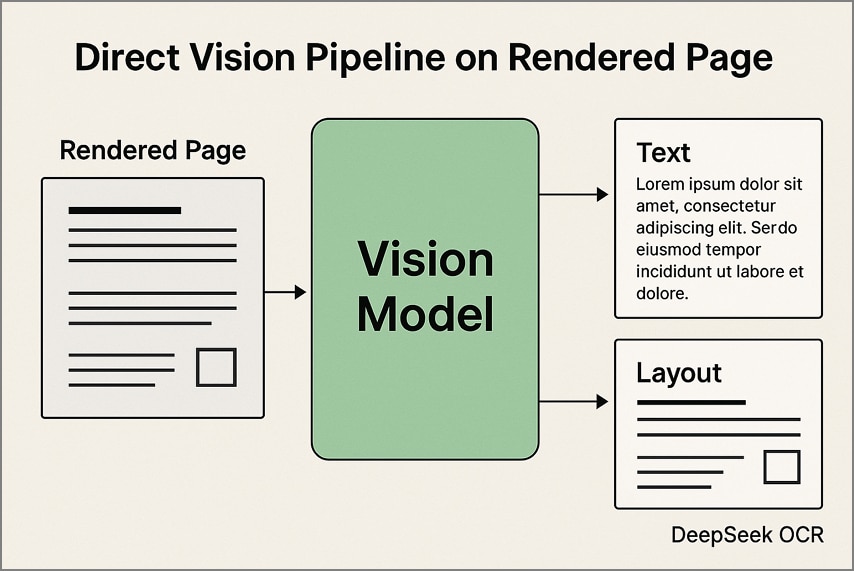
1. خط أنابيب الرؤية المباشرة على الصفحات المعروضة
في هذا النهج، يتم تحويل كل صفحة PDF إلى صورة بدقة ثابتة قبل معالجتها من خلال DeepSeek OCR. يستخرج النموذج كلاً من النص وتفاصيل التخطيط مباشرة من الصور، مع الحفاظ على الجداول والأعمدة والرسوم التخطيطية في بنيتها الأصلية. هذه الطريقة فعالة بشكل خاص للمستندات الممسوحة ضوئيًا والتخطيطات المعقدة بصريًا.
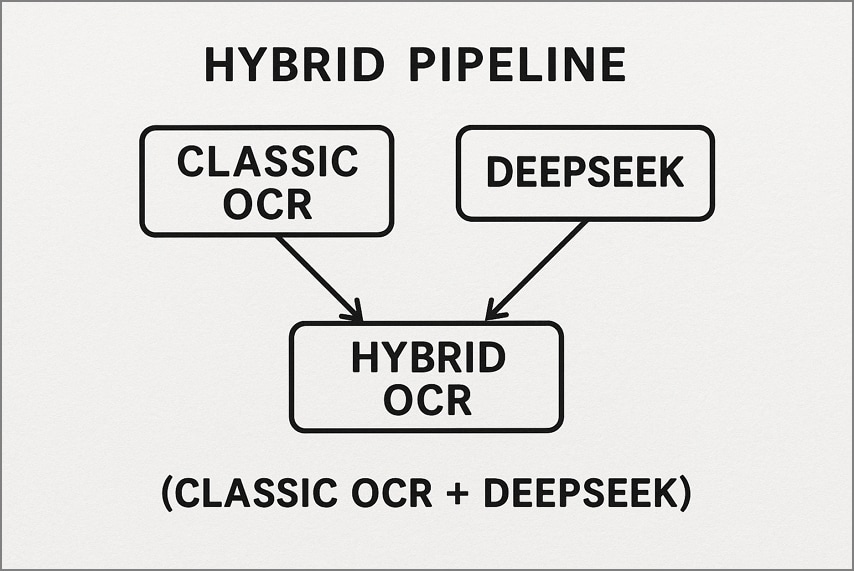
2. خط الأنابيب الهجين (OCR التقليدي + DeepSeek)
هنا، تتعامل أداة OCR تقليدية مثل Tesseract أولاً مع الصفحات البسيطة عالية الجودة لإنتاج مخرجات نصية سريعة. يتم تمرير الصفحات الأكثر تعقيدًا أو الضوضاء فقط إلى DeepSeek OCR لإعادة بناء التخطيط العميق والفهم الدلالي. يقلل سير العمل هذا من التكلفة والتأخير مع تحقيق دقة ممتازة على المستندات الصعبة.
الحالات الحدية
بعض المستندات أصعب في المعالجة من صفحات النص القياسية، لذا من المهم التعامل مع الحالات الحدية بعناية للحصول على أفضل دقة للتعرف البصري على الحروف.
- المجلات/الصحف متعددة الأعمدة: فرض ترتيب العمود الصحيح مع تجميع السطر بعد OCR، تفضيل 300 DPI، التقسيم لكل عمود للصفحات الكثيفة.
- الأختام/العلامات المائية/الأختام: قناع أو فصل التراكبات قبل OCR لتجنب النص الخاطئ والدمج الخاطئ، ثم أعد إدراجها بعد ذلك.
- الانحراف/الدوران: إزالة انحراف الصفحات أولاً، اكتشاف الاتجاه بشكل موثوق، ثم تشغيل OCR مرة أخرى على الصفحات التي تم تدويرها.
- مسح ضوئي منخفض DPI: أخذ عينات لأعلى بحوالي 1.5-2 مرة وتحسين، وإلا يفضل إعادة المسح بدقة أعلى.
- الجداول والنماذج: تشغيل كاشف الجدول أو خطوة محاذاة الرأس لإصلاح الخلايا المنقسمة، ثم التحقق من المجاميع والحقول الرئيسية.
- الخطوط/الرياضيات/الكود: استخدام بلاط بدقة أعلى للمعادلات وكتل التعليمات البرمجية والخطوط الصغيرة جدًا، والحفاظ على تباعد أحادي المسافة مع أسوار الكود.
لماذا المعالجة اللاحقة مهمة
المعالجة اللاحقة هي التنظيف البسيط بعد استخراج النص، بحيث تكون النتيجة صحيحة. وهي تصحح الأعمدة المختلطة، والجداول المكسورة، والعناوين الفوضوية، والأختام التي تمت قراءتها عن طريق الخطأ ككلمات. إذا بدا شيء ما خاطئًا، أعد تشغيل تلك الصفحة بجودة أعلى وتحقق من المجاميع والتواريخ والمعرفات.
الجزء 6. Ollama + DeepSeek OCR (فكرة محلية أولاً)
إنه إطار عمل خفيف الوزن يعمل على تشغيل نماذج اللغة الكبيرة بالكامل على جهاز الكمبيوتر الخاص بك، مع واجهة برمجة تطبيقات محلية بسيطة وواجهة سطر أوامر. يتيح لك Ollama DeepSeek OCR معالجة المستندات الممسوحة ضوئيًا وملفات PDF من البداية إلى النهاية على جهازك لتجنب اعتماديات السحابة والحفاظ على البنية في المخرجات مثل Markdown أو JSON.
التكامل المجتمعي والأمثلة
في هذا القسم، سنستكشف المشاريع المجتمعية التي تجمع بين DeepSeek OCR ونماذج Ollama لمعالجة المستندات المحلية واستخراجها وتحليلها.
- استوديو Streamlit OCR: تستوعب لوحة معلومات Streamlit ملفات PDF والصور وتشغل DeepSeek OCR للنص المنظم. ثم يجيب هذا النموذج على أسئلة المستخدم حول المحتوى المستخرج محليًا.
- مستخرج Markdown + Ollama QA: يتم استخدام أداة تحويل الصورة إلى Markdown لتحويل صور الصفحة إلى Markdown نظيف للاستخدام اللاحق. يلخص نموذج دردشة Ollama المستندات ويستخرج الحقول الرئيسية من ملفات PDF والصور الممسوحة ضوئيًا.
- محلل محلي + واجهة برمجة تطبيقات Ollama: خدمة مشاهدة المجلدات تقوم بمعالجة OCR للملفات الجديدة باستخدام DeepSeek عند وصولها. توفر نقطة نهاية Ollama محلية للبحث والأسئلة والأجوبة والتنقيح وأتمتة سير العمل.
لماذا التنسيق المحلي يساعد
بعد تشغيل Ollama مع DeepSeek OCR محليًا، دعونا نستكشف بعض المزايا الرئيسية لهذا الإعداد.
- احتفظ بالمستندات على الجهاز لتلبية سياسات البيانات الصارمة وتقليل التعرض للاختراق أثناء عمليات التدقيق.
- تشغيل بالكامل بدون إنترنت في المختبرات الآمنة والشبكات المعزولة لاختبار الامتثال.
- تجنب تأخيرات الشبكة، والتحكم في التجميع والتخزين المؤقت محليًا، وتثبيت الإنتاجية لملفات PDF الكبيرة.
الجزء 7. مسار أسرع للفرق اليومية: PDFelement (التعرف البصري على الحروف وتنظيف PDF بدون كود)
غالبًا ما يواجه العديد من المستخدمين بدون خبرة تقنية صعوبة في استخراج النص من ملفات PDF الممسوحة ضوئيًا أو المستندات القائمة على الصور. بجانب DeepSeek OCR، يبحثون عن أدوات توفر معالجة OCR سهلة وتنظيف المستندات واستخراج النصوص السريع دون معرفة تقنية. هنا يأتي دور PDFelement الذي يبسط استخراج PDF مع OCR بدون كود ويساعد الفرق على تحويل المستندات إلى تنسيقات قابلة للبحث في ثوانٍ.
على عكس الأدوات الأخرى، يمكن للمستخدمين أيضًا التسطير، وإضافة علامة مائية، وإدراج خلفية، والدردشة مع الذكاء الاصطناعي بخصوص ملفات PDF الخاصة بهم. يوفر PDFelement مساحة تخزين تصل إلى 20 جيجابايت لحفظ بياناتك داخل هذه الأداة ومشاركتها مباشرة عبر منصات التواصل الاجتماعي. علاوة على ذلك، لجعل المنطقة المستهدفة قابلة للتحرير، فإنه يوفر خيار "منطقة OCR" لاختيار أجزاء محددة من المستند.
دليل نهائي لـ OCR PDF بدون برمجة في PDFelement
بعد التعرف على أفضل أداة OCR PDF لغير المبرمجين، اتبع سير العمل خطوة بخطوة هذا لمعالجة ملفات PDF بسرعة كبديل لـ DeepSeek OCR API:
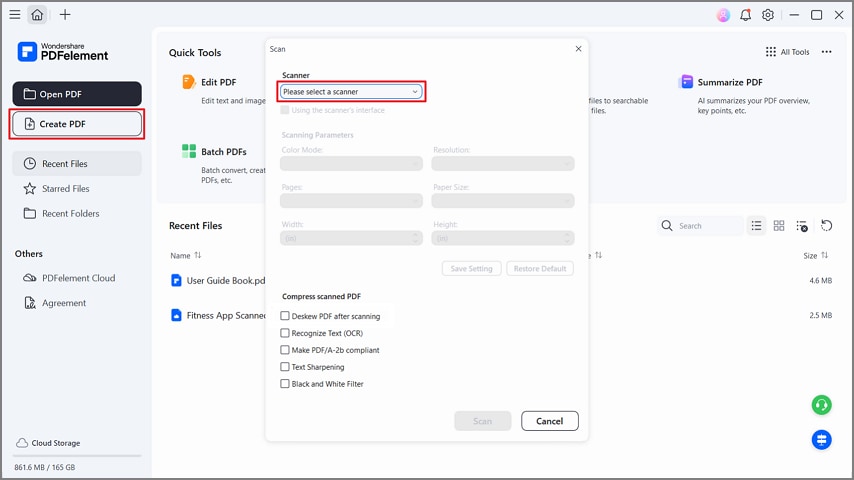
الخطوة 1إنشاء PDF من الماسح الضوئي
بمجرد الدخول إلى الأداة، اضغط على زر "إنشاء PDF" واختر خيار "من الماسح الضوئي" من القائمة المنسدلة. بعد ذلك، اختر الماسح الضوئي الخاص بك وحدد خيار "تصحيح ميل PDF بعد المسح الضوئي". تحول هذه الأداة عمليات المسح إلى نص قابل للبحث أو قابل للتحرير مع دعم سطح المكتب.
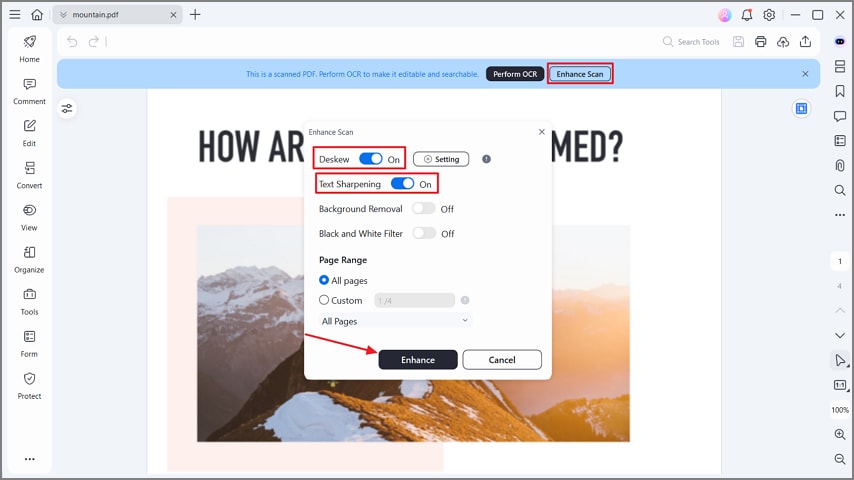
الخطوة 2تحسين ملف PDF الخاص بك
بعد إنشاء ملف PDF الممسوح ضوئيًا، اضغط على زر "تحسين المسح". بعد ذلك، قم بتبديل خيارات "تصحيح الميل" و"تحسين النص" واضغط على زر "تحسين" في النافذة المنبثقة. سيقوم ذلك بتحسين وضوح النص في PDF لتعزيز دقة OCR في المسحات الضوئية الرديئة.
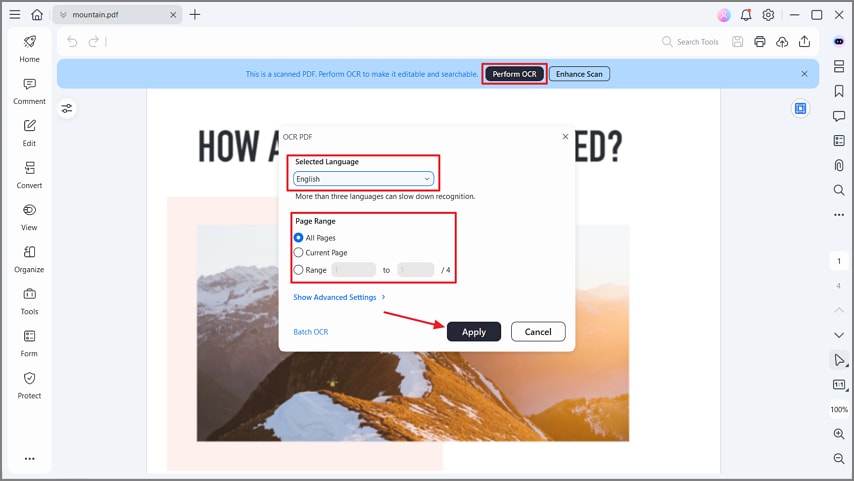
الخطوة 3تنفيذ OCR للنص
الآن، اضغط على زر "تنفيذ OCR" واختر اللغة الصحيحة. بعد ذلك، حدد "نطاق الصفحة" المحدد واضغط على زر "تطبيق" لبدء عملية OCR. سيؤدي هذا إلى استخراج النص من ملف PDF الخاص بك لجعله قابلًا للبحث والتحرير للمراجعة أو التصدير.
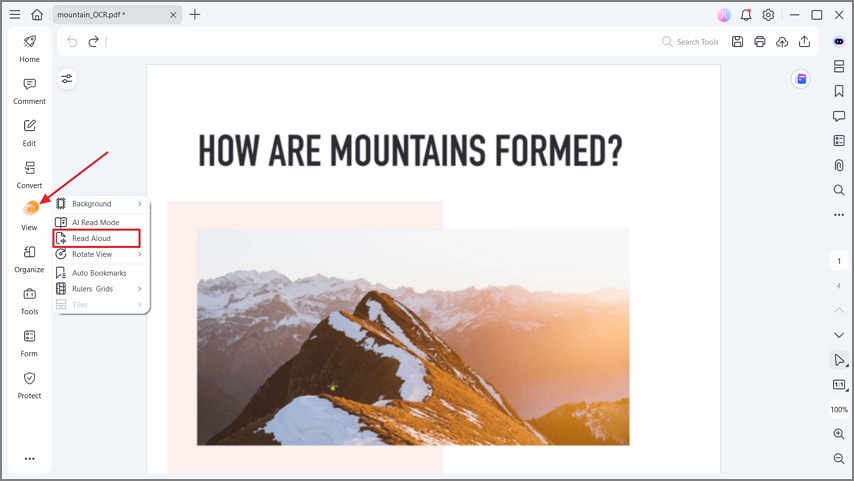
الخطوة 4قراءة PDF بصوت عالٍ
بمجرد الانتهاء من OCR، اضغط على خيار "عرض" من القائمة الجانبية واضغط على خيار "القراءة بصوت عالٍ" للاستماع إلى نص PDF الخاص بك. يمكنك إيقاف وتعليق الاستماع في أي وقت. تتيح لك هذه الميزة تدقيق ملفات PDF الخاصة بك لتحديد أي أخطاء.
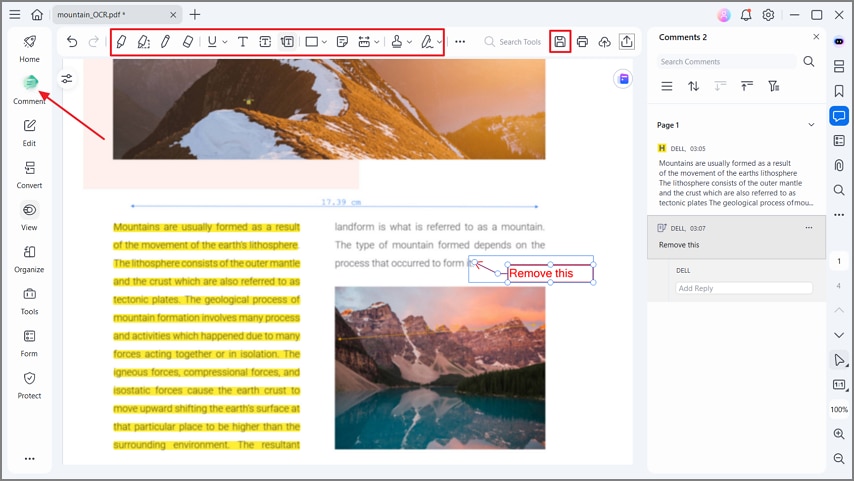
الخطوة 5التعليق وتصدير PDF
انقر على زر "تعليق" واستخدم الأدوات في شريط الأدوات لتمييز النص وإضافة تعليقات إلى ملف PDF. أخيرًا، اضغط على زر "حفظ" لتصدير ملف PDF. تساعد ميزة التعليق أيضًا في إضافة أختام، ورسم أشكال، وإرفاق ملصقات، والتسطير أو الشطب على النص لمراجعة المستندات بشكل أفضل.
الجزء 8. DeepSeek OCR مقابل PDFelement مقابل OCR التقليدي - متى تستخدم ماذا
بعد استكشاف أفضل بديل لـ DeepSeek OCR، دعنا نرى ما هي الأدوات المثالية لحالات الاستخدام المختلفة وسير عمل المستندات.
DeepSeek OCR
أفضل للمطورين الذين يتطلبون التفكير المنطقي للسياق الطويل، وRAG فعال للرموز، ومخرجات Markdown أو JSON المدركة للتخطيط. توقع إعداد وعمليات تشغيل، بما في ذلك تحجيم GPU/VRAM، واختيارات الدفعات أو التقسيم، وضبط الحالات الحدية في بعض الأحيان.
Wondershare PDFelement
خيار صلب للعمل اليومي مع المستندات التي تحتاج إلى OCR متعدد اللغات، وتحسين المسح المرئي، والتعليق، والمراجعة. تعمل عمليات التصدير بنقرة واحدة إلى Word أو Excel على تبسيط عمليات التسليم، وتتجنب الفرق البرمجة أو إدارة GPU.
مكتبات OCR التقليدية
تعمل بشكل أفضل على الإنتاجية العالية عندما تكون التخطيطات بسيطة ومتسقة عبر الدفعات. أضف قواعد خفيفة أو تمرير LLM مستهدف فقط على الصفحات الصعبة لإضافة دلالات دون دفع التكلفة في كل مكان. ألق نظرة على جدول المقارنة أدناه لفهم كيف تناسب كل أداة سير العمل واحتياجات المستخدم المختلفة.
| الأداة | التركيز | الإعداد | السياق الطويل | التنظيف | متعدد اللغات | الأفضل لـ |
| DeepSeek OCR | سير عمل المطورين، RAG | تقني | معتدل | محدود/برمجي | معتدل | المطورين، النماذج الأولية، البحث، خطوط أنابيب RAG |
| PDFelement | تحرير ومراجعة المستندات | بدون برمجة | عالي | أدوات واجهة مستخدم رسومية كاملة | عالي | فرق الأعمال، العمليات، الامتثال، الأرشفة |
| OCR التقليدي | معالجة الدفعات، المستندات البسيطة | تقني | متوسط | قائم على البرمجة النصية | معتدل | وظائف الدفعات، المكاتب الخلفية، التخطيطات البسيطة |
الجزء 9. كتيبات خطوة بخطوة (جاهزة للنسخ)
الآن بعد أن فهمت كيف تناسب كل أداة سير العمل المختلفة، دعنا ننتقل إلى أدلة الإعداد السريع. توضح كتيبات التشغيل السريعة التالية كيفية استخدام DeepSeek OCR GitHub وخيارات أخرى لكل من المطورين وغير المطورين.
المطورون - جرب DeepSeek OCR API في 10 دقائق
- الخطوة 1. قم بإنشاء مفتاح API من "الحساب" أو "مفاتيح API" وضبط "DEEPSEEK_API_KEY".
- الخطوة 2. قم بإعداد POST إلى "/v1/chat/completions" مع النموذج، وموجه النظام، ومخطط المحتوى.
- الخطوة 3. قم بعرض صفحات PDF إلى PNG بـ DPI ثابت وأرفق base64 في "الرسائل".
- الخطوة 4. اطلب JSON صارم أو Markdown، ثم قم بتحليل حقل "المحتوى" بأمان.
- الخطوة 5. تحقق من صحة الحقول، وتعامل مع إعادة المحاولات والاحتفاظ في "الوظائف" أو "التخزين".
المطورون - التشغيل من GitHub (محلي)
- الخطوة 1. "استنسخ" المستودع على جهاز جاهز لـ CUDA وتحقق من إصدارات برنامج التشغيل أو مجموعة الأدوات.
- الخطوة 2. قم بإنشاء venv، وتشغيل "pip install -r requirements.txt"، وتنزيل "الأوزان"، وضبط "MODEL_PATH".
- الخطوة 3. حول PDF إلى صور بـ DPI متناسق، قم بتشغيل "infer.py --input pages --output out --format markdown".
- الخطوة 4. سجل "زمن الاستجابة"، و"VRAM"، و"الإنتاجية"، وقارن الدقة مع OCR الأساسي.
غير المطورين - OCR نظيف لملفات PDF في PDFelement
- الخطوة 1. أولاً، انقر على "إنشاء PDF" و"من الماسح الضوئي" للمسح. ثم، اضغط على زر "تحسين المسح" وقم بتمكين خيارات "تصحيح الميل" و"تحسين النص".
- الخطوة 2. اضغط على "تنفيذ OCR"، حدد "اللغة"، اختر "نص قابل للتحرير" أو "نص قابل للبحث في الصورة"، ثم انقر على "تطبيق".
- الخطوة 3. استخدم "قراءة الذكاء الاصطناعي" أو "القراءة بصوت عالٍ" للتدقيق من خلال الاستماع، وإصلاح الأخطاء التي تلاحظها أثناء التشغيل.
- الخطوة 4. الآن، اضغط على زر "تعليق" في اللوحة اليسرى لإضافة "تمييزات"، "تعليقات"، و"ملصقات" للمراجعة.
- الخطوة 5. أخيرًا، اضغط على "تصدير" لحفظ ملف PDF قابل للبحث للتسليم.
الجزء 10. اعتبارات معروفة (الدقة، الأمن، التوفر)
قبل اعتماده بالكامل في الإنتاج، من المهم مراجعة بعض العوامل العملية التي تؤثر على كيفية أداء DeepSeek OCR API في الاستخدام العملي.
- الدقة: تختلف النتائج حسب تخطيط الصفحة وجودة المسح، لذلك اختبر الأداء على مجموعة المستندات الخاصة بك أولاً. استخدم مستندات تمثيلية، وأدرج جداول وأعمدة، وتتبع الأخطاء مثل الانقسامات والدمج.
- الأمن والامتثال: راجع معالجة البيانات من قبل المورد، والتخزين، والاحتفاظ، وتجنب إرسال الملفات الحساسة دون تقييم. أضف تنقيح قبل التحميل، وقيد الوصول، ووثق الموافقات لتلبية عمليات التدقيق والسياسات الداخلية.
- التوفر والموثوقية: يمكن أن تواجه الخدمات انقطاعات أو تقييدًا، لذلك أضف إعادة المحاولات، والتراجع، وبدائل مرنة محليًا. راقب معدلات الخطأ وزمن الاستجابة، وقم بالتنبيه عن الإخفاقات، وحدد دفاتر تشغيل واضحة للحوادث.
- الإنتاجية والتوسع: عامل الإنتاجية البارزة كإرشادية فقط، وقم بإجراء اختبار مقارنة على جهازك بـ DPI ثابت. قم بقياس الصفحات في الساعة، واستخدام GPU أو CPU، والتكاليف، ثم قم بتحجيم الدفعات والتخزين المؤقت بشكل صحيح.
يسأل الناس أيضًا
-
ما هو DeepSeek OCR ولماذا تعتبر "الضغط البصري" مهمًا؟
يقوم DeepSeek OCR بضغط محتوى الصفحة في رموز مرئية مدمجة تحافظ على البنية وتقلل استخدام الرموز للنماذج اللاحقة. هذا مهم لأنه يتيح تغطية مستندات أكبر ضمن حدود السياق الثابتة ويخفض تكلفة الاستدلال مع الحفاظ على الجداول والقوائم والتخطيط سليمًا. -
أين يوجد مستودع DeepSeek OCR GitHub؟
يوفر المستودع الرسمي الكود والأمثلة والمراجع لتشغيل الاستدلال المحلي وتكييف خطوط الأنابيب. قم باستنساخه لتقييم المخرجات مقابل OCR الأساسي الخاص بك، وتخصيص المطالبات، وتصدير Markdown أو JSON للتكامل. -
هل هناك DeepSeek OCR API وهل هو متوافق مع OpenAI؟
يوجد API يقبل طلبات دردشة على غرار OpenAI مع صور أو صفحات PDF معروضة. يمكنك طلب JSON صارم أو Markdown، ثم تحليل محتوى الاستجابة باستخدام المكتبات وسير العمل القياسية. -
كيف أستخدمه مع ملفات PDF؟
قم بعرض كل صفحة PDF إلى صور بـ DPI متناسق، قم بتشغيل OCR المرئي، ثم قم بربط الصفحات ومعالجة الجداول والقوائم لاحقًا. بدلاً من ذلك، قم بتشغيل OCR التقليدي للنص الخام أولاً، ثم طبق DeepSeek لدلالات التخطيط، وإصلاح الهيكل، وإنشاء markdown. -
هل يمكنني تشغيله مع Ollama محليًا؟
تقرن إعدادات المجتمع مخرجات DeepSeek مع نماذج Ollama المحلية للأسئلة والأجوبة، والاستخراج، والتحقق. تشمل الأنماط النموذجية لوحات معلومات Streamlit، ومعالجات المجلدات المراقبة، ومحللات المستندات الخفيفة دون الاعتماد على خدمات السحابة الخارجية. -
أحتاج فقط إلى OCR ملف PDF ممسوح ضوئيًا مع دعم متعدد اللغات - ما هو الأسهل؟
استخدم PDFelement لسير عمل بدون برمجة يتعامل مع تصحيح الميل، وإزالة الضوضاء، و OCR متعدد اللغات بموثوقية. قم بتحسين المسح، واختر اللغة الصحيحة، والتدقيق باستخدام القراءة بصوت عالٍ أو قراءة الذكاء الاصطناعي، والتعليق، وتصدير ملف PDF نظيف وقابل للبحث.
